& meet dozens of singles today!
User blogs
Batteries are the latest landing pad for investors.
In the past week alone, two companies have announced plans to become publicly traded companies by merging with special purpose acquisition companies. European battery manufacturer FREYR said Friday it would become a publicly traded company through a special purpose acquisition vehicle with a valuation at $1.4 billion. Houston area startup Microvast announced Monday its own SPAC, at a $3 billion valuation.
A $4.4 billion combined valuation for two companies with a little over $100 million in revenue (FREYR has yet to manufacture a battery) would seem absurd were it not for the incredible demand for batteries that’s coming.
Legacy automakers like GM and Ford have committed billions of dollars to shifting their portfolios to electric models. GM said last year it will spend $27 billion over the next five years on the development of electric vehicles and automated technology. Meanwhile, a number of newer entrants are either preparing to begin production of their electric vehicles or scaling up. Rivian, for instance, will begin delivering its electric pickup truck this summer. The company has also been tapped by Amazon to build thousands of electric vans.
The U.S. government could end up driving some of that demand. President Biden announced last week that the U.S. government would replace the entire federal fleet of cars, trucks and SUVs with electric vehicles manufactured in the U.S. That’s 645,047 vehicles. That’s going to mean a lot of new batteries need to be made to supply GM and Ford, but also U.S.-based upstarts like Fisker, Canoo, Rivian, Proterra, Lion Electric and Tesla.
Meanwhile, some of the largest cities in the world are planning their own electrification initiatives. Shanghai is hoping to have electric vehicles represent roughly half of all new vehicle purchases by 2025 and all public buses, taxis, delivery trucks, and government vehicles will be zero-emission by the same period, according to research from the Royal Bank of Canada.
The Chinese market for electric vehicles is one of the world’s largest and one where policy is significantly ahead of the rest of the world.
A potential windfall from China’s EV market is likely one reason for the significant investment into Microvast by investors including the Oshkosh Corp., a 100 year-old industrial vehicles manufacturer; the $8.67 trillion money management firm, BlackRock; Koch Strategic Platforms; and InterPrivate, a private equity fund manager. That’s because Microvast’s previous backers include CDH Investments and CITIC Securities, two of the most well-connected private equity and financial services firms in China.
So is the company’s focus on commercial and industrial vehicles. Microvast believes that the market for commercial electric vehicles could be $30 billion in the near term. Currently, commercial EV sales represent just 1.5% of the market, but that penetration is supposed to climb to 9% by 2025, according to the company.
“In 2008, we set out to power a mobility revolution by building disruptive battery technologies that would allow electric vehicles to compete with internal combustion engine vehicles,” said Microvast chief executive Yang Wu, in a statement. “Since that time we have launched three generations of battery technologies that have provided our customers with battery performance far superior to our competitors and that successfully satisfy, over many years of operation, the stringent requirements of commercial vehicle operators.”
Roughly 30,000 vehicles are using Microvast’s batteries and the investment in Microvast includes about $822 million in cash that will finance the expansion of its manufacturing capacity to hit 9 gigawatt hours by 2022. The money should help Microvast meet its contractual obligations which account for about $1.5 billion in total value, according to the company.
If Chinese investors stand to win big in the upcoming Microvast public offering, a clutch of American investors and one giant Japanese corporation are waiting expectantly for FREYR’s public offering. Northbridge Venture Partners, CRV, and Itochu Corp. are all going to see gains from FREYR’s exit — even if they’re not backers of the European company.
Those three firms, along with the International Finance Corp. are investors in 24m, the Boston-based startup licensing its technology to FREYR to make its batteries.
FREYR’s public offering will also be another win for Yet-Ming Chiang, a serial entrepreneur and professor who has a long and storied history of developing innovations in the battery and materials science industry.
The MIT professor has been working on sustainable technologies for the last two decades, first at the now-defunct battery startup A123 Systems and then with a slew of startups like the 3D printing company Desktop Metal; lithium-ion battery technology developer, 24m; the energy storage system designer, Form Energy; and Baseload Renewables, another early-stage energy storage startup.
Desktop Metal went public last year after it was acquired by a Special Purpose Acquisition Company, and now 24m is getting a potential boost from a big cash infusion into one of its European manufacturing partners, FREYR.
The Norwegian company, which has plans to build five modular battery manufacturing facilities around a site in its home country intends to develop up to 43 gigawatt hours of clean batteries over the next four years.
For FREYR chief executive Tom Jensen there were two main draws for the 24m technology. “It’s the production process itself,” said Jensen. “What they basically do is they mix the electrolyte with the active material, which allows them to make thicker electrodes and reduce the inactive materials in the battery. Beyond that, when you actually do that you remove the need fo a number of traditional production steps… Compared to conventional lithium battery production it reduces production from 15 steps to 5 steps.”
Those process efficiencies combined with the higher volumes of energy bearing material in the cell leads to a fundamental disruption in the battery production process.
Jensen said the company would need $2.5 billion to fully realize its plans, but that the float should get FREYR there. The company is merging with Alussa Energy Acquisition Corp. in a SPAC backed by investors including Koch Strategic Platforms, Glencore, Fidelity Management & Research Company LLC, Franklin Templeton, Sylebra Capital and Van Eck Associates.
All of these investments are necessary if the world is to meet targets for vehicle electrification on the timelines that have been established.
As the Royal Bank of Canada noted in a December report on the electric vehicle industry. “We estimate that globally, battery electric vehicles (BEVs) will represent ~3% of 2020 global demand, while plug-in hybrid-electric vehicles (PHEVs) will represent another ~1.3%,” according to RBC’s figures. “But we see robust growth off these low figures. By 2025, when growth is still primarily regulatory driven, we see ~11% BEV global penetration of new demand representing a ~40% CAGR from 2020’s levels and ~5% PHEV penetration representing a ~35% CAGR. By 2025, we see BEV penetration in Western Europe at ~20%, China at ~17.5%, and the US at 7%. Comparatively, we expect internal combustion engine (ICE) vehicles to grow (cyclically) at a 2% CAGR through 2025. On a pure unit basis, we see “peak ICE” in 2024.”
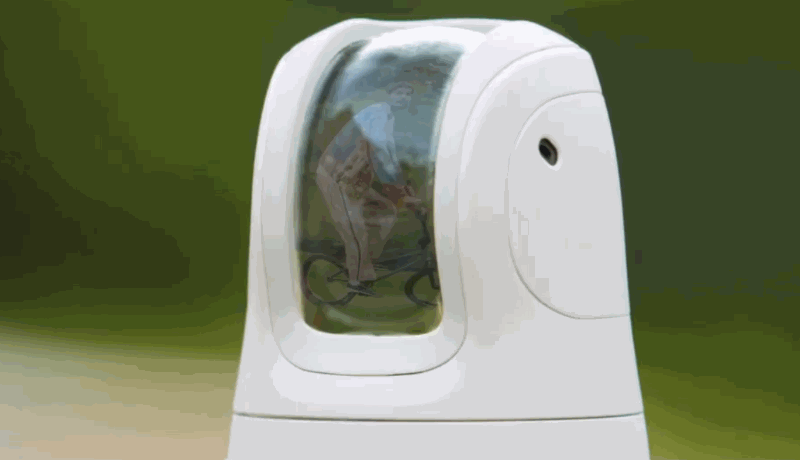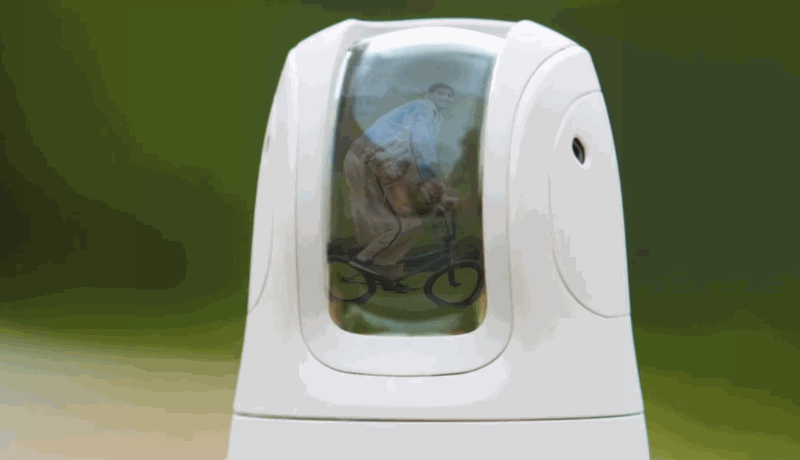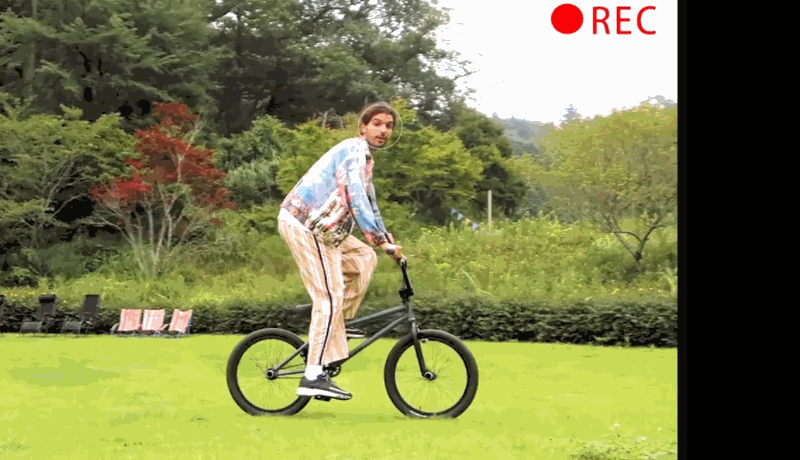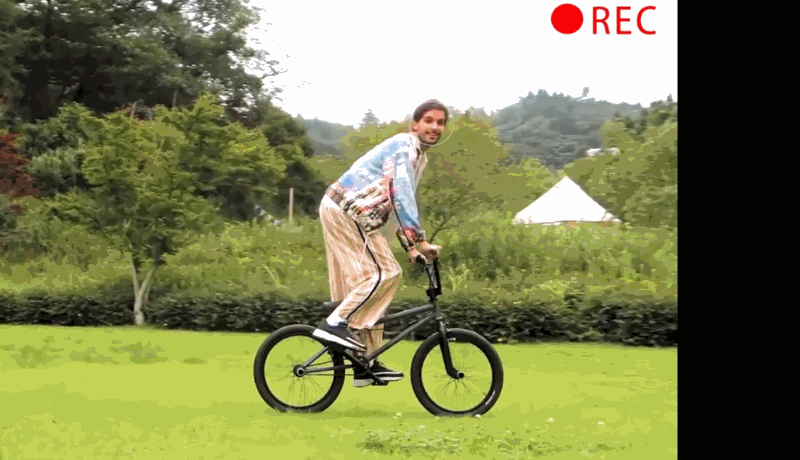
Canon is embracing the AI-infused future with a strange new robotic camera called the PowerShot PICK. This little device swivels and keeps its subjects in view, taking commands or snapping shots on its own.
It’s a bit like a smart security camera or Facebook’s Portal, but meant to be taken with you wherever you go, attached to a selfie stick, and so on. Its body is about the size of a juice box, making it portable but not quite pocketable.
The camera company appears to be hedging its bets by offering the PICK not as a retail product but through the Japanese crowdfunding site Makuake, where it has already blasted through its trumpery $10,000 goal (currently at about ten times that, which is still just a fraction of what it must have cost to develop this thing).
“PICK… stop watching me.” “I’m afraid I can’t do that, Dennis.”
A promo video for the campaign shows the PICK being used in a variety of circumstances: recognizing faces and shooting during a party; tracking a person riding a bike around their yard; activating itself on demand in someone’s kitchen and following their position.
The idea is fun — a device you just set down and it snaps candid photos while you do your thing, or keeps you in view while you do you vlog — but the proof is in the pudding.
The sensor is small, an old point-and-shoot’s 1/2.3″ 12MP, though the F/2.8 zoom lens and image stabilization should help it out in uneven light. We won’t know what the shots look like until they send a few of these out to backers and reviewers.
Is this a ridiculous dead-end gadget from a company desperate to escape the photography industry’s death spiral? Or is it a smart, easy solution for people tired of thinking “ah – someone should get a shot of this”? You can still, of course, tweak and operate the camera from a companion app.
One thing it doesn’t appear to be is a webcam, which seems like a missed opportunity. A swiveling, smart webcam that takes voice commands would be a godsend to many people tired of taking every call in the same shabby rectangle of their improvised home office. Now that we’ve all thoroughly stopped caring about “looking professional” (and if you haven’t stopped… this is your cue) maybe we can start taking meetings while cleaning the kitchen or sitting on the patio.
Hopefully this little experimental device bears fruit for Canon and we’ll all have robot camera buddies we take around with us everywhere. Sounds creepy now, sure, but just wait a few years.
Last year I penned a post positing that Salesforce’s propensity to purchase mature enterprise companies not only provided new technology, but was also helping to produce a profusion of executive talent.. As though to prove my point, the company announced today that it was promoting former Vlocity CEO, David Schmaier to president and chief product officer.
Schmaier came to the organization last year when Salesforce acquired his company for $1.33 billion. It seemed like a good match given that Vlocity sold Salesforce solutions designed for certain niches like financial services, health, energy and utilities and government and nonprofits.
As a result, Schmaier knew the product set and the company well. Last June, he was named CEO of the Salesforce Industries division, which was created after the Vlocity acquisition. The connection was clear to Schmaier as he told me at the time of his promotion last year:
“I’ve been involved in various mergers and acquisitions over my 30-year career, and this is the most unique one I’ve ever seen because the products are already 100% integrated because we built our six vertical applications on top of the Salesforce platform. So they’re already 100% Salesforce, which is really kind of amazing. So that’s going to make this that much simpler,” he said.
Brent Leary, founder and principal analyst at CRM Essentials, says that Schmaier’s history in building Vlocity makes this promotion pretty easy given the direction of the company, as well as the industry. “Over the last several years we’ve seen just how important developing industry-specific solutions have become to the major players in the space, and Schmaier’s promotion reaffirms this while illustrating how important creating verticals is to their platform [and] to the future of Salesforce,” he told me.
In a Q&A on the Salesforce website announcing the promotion, Schmaier talked about the challenges companies faced in the last year. “There’s no question 2020 was a challenging year. We are operating in this all-digital, work from anywhere world and things won’t go back to where they were, nor should they. One of the silver linings has been seeing what companies can do when there is no alternative and the imperative is to connect with their customers in entirely new ways,”
In his new position it will be Schmaier’s job to figure out how to help them do that.
Soon all tech news will be fintech news, all fintech news will be trading platform news and all trading platform news will concern the business mechanics of such services.
So, after looking into Robinhood’s fourth-quarter payment for order flow (PFOF) revenues this morning, we’re back with a related story. This time, however, we’re talking about Public.
Public, like Robinhood, is a zero-cost trading service. Its founders have worked to build a community-first platform, including offering ways to let groups chat about their investments.
And like Robinhood, Public has seen its growth skyrocket in recent days. Company representatives told TechCrunch today it was seeing “steady ~30%” month-over-month growth until Thursday, when “new user signups went up 20x.”
Both share strong backing from investors: Robinhood raised billions in new capital this week to ensure it has enough cash to meet clearinghouse deposit requirements. It managed to do so in part because its Q4 2020 numbers show that its PFOF business is ticking along nicely.
Public, flush with a recent $65 million Series C, took a different tack this morning and announced it would “stop participating in the practice of Payment for Order Flow.”
ANNOUNCEMENT: To better align our incentives with those of our members, we will stop participating in the practice of Payment for Order Flow.https://t.co/s9Vd2MyLcJ
— Public.com (@public) February 1, 2021
To which we say … all right.
On one level, this is neat. Public is not going to sell its order flow to market makers for fees. That’s good for users, but how will it make up the lost revenue? Tips, which will prove an interesting experiment in monetization.
TechCrunch asked the company if it believes tips will compensate for PFOF revenue, to which founders Leif Abraham and Jannick Malling replied via email that they were “optimistic that the difference will be offset by the optional tipping feature.”
However, dropping payment for order flow is only so brave a move from Public. After all, Public was not making Robinhood-level amounts of fetti from its PFOF business. Indeed, as we wrote when Public raised its Series C:
Before chatting with Public, I dug into its trading partner Apex’s filings to learn about its payment for order flow results from its recent filings. The resulting sums are somewhat modest for Apex’s collected clients. This means that Public’s revenue metrics, a portion of the aggregate sums, are even more unassuming.
Source: https://techcrunch.com/2021/02/01/trading-app-public-drops-payment-for-order-flow-in-favor-of-tips/
Nathalie Walton almost didn’t become a mother. Her risky pregnancy caused her placenta to burst during childbirth, almost killing her and her son last year. Walton, who feels lucky to have survived, says the haunting experience made her an example of a reality she had long known: To be a pregnant Black woman is to be at risk, regardless of economic background.
The stress of her pregnancy led Walton to download Expectful, a meditation and sleep app for new mothers. She recalls stabilizing, emotionally and physically, within a week, bringing an otherwise “soft landing” to a volatile pregnancy.
Weeks after delivering her son, Everett, Walton just so happened to hear of an advisory role opening at Expectful. Even though she was mid-maternity leave from her managerial role at Airbnb, she jumped at the opportunity.
“I definitely had a full-time job, I had a newborn baby,” Walton said. But, she says, it was an opportunity to be entrepreneurial in a sector she cared about. Even if it was just for a few months.
And now, Walton is the chief executive of the company. The business is pivoting its product strategy to grow beyond recorded meditations. Walton helped it raise its first millions in venture capital, making her one of the few dozen Black female founders to do so. New financing and the boom of the mental health focus amid the coronavirus pandemic puts Expectful in a coveted spot. And it puts Walton, who is at the helm of a company for the first time, in a pressure-cooker spotlight.
Even in the world of startups, going from user to chief executive in less than a year is a remarkable feat. But it’s not one that she rushed.
A quarter-life crisis
Walton graduated from Georgetown and immediately joined the New York banking world. After a few years as an analyst at JP Morgan, though, she became unsatisfied with the work.
“I think I had a quarter-life crisis,” Walton said. Searching for new opportunities, she ended up at a prospective students day at Stanford University in what would become a pivotal moment in her life.
“For the first time, I met entrepreneurs and saw an actual concept that you can pursue a career you like, be successful and make a difference in the world,” she said. Walton eventually applied, and got accepted, to Stanford Graduate School of Business (GSB), a prestigious program that produces founders and top executives. It was then that she realized she wanted to be a chief executive one day.
“I admired them, but I just didn’t see the pathway for me to get there,” she said, of the entrepreneurs she met, who were then largely white and male. “I didn’t have the confidence.”
So, she set that hope aside and pursued intrapreneurship, which would let her join a stable organization and act as a mini-founder within it. Employees in this role are tasked with building a startup within a startup, whether that is rooting an innovative idea or leading an experiential team. Corporations have long embraced this idea to bring momentum to otherwise red-tapey processes.
Walton joined eBay and soon rose to work as the head of business operations and development. Her work helped the company break into 3D printing.
Over the years, this has been the defining characteristic of Walton: join an organization, build a scrappy idea from scratch, and then do it all over again. She has held roles in Airbnb and Google that all required her to have the agility of a founder convincing people on a moonshot vision, and the rigor of a manager who can get a deal done.
She had the same vision heading into an advisory role at Expectful. But when Walton landed a key Expectful partnership with Johnson & Johnson, then-CEO and founder Mark Krassner had an idea.
‘It was on my mind from day No. 1’
Before starting Expectful, Krassner experienced the benefits of meditation firsthand. He also saw his mother face depression, which made him realize how meditation could have a positive impact on others. After seeing research that showed how meditation could positively impact a pregnancy, he began thinking of a solution in this cross-section. He eventually started a course on Teachable, a startup that lets anyone create and monetize an online class, with 15 moms and a guided meditation.
Over time, the idea stuck. Krassner eventually turned his course into a 12-person startup. Under his leadership, Expectful grew to profitability and over 13,000 paid users. Its conversion rate from free to paid users was five times higher than industry standards, the company claims.
That said, from the moment Mark Krassner started Expectful, he knew he was an unlikely founder. He doesn’t have any children, so leading a meditation and sleep app for new mothers comes with its own hurdles.
“As a male founder with no kids, it was on my mind from day No. 1,” Krassner said. He eventually wanted to put a female at the head of the company, he says. Walton was the obvious choice.
Walton returned to Airbnb after her maternity leave right as Airbnb had aggressive COVID-19 layoffs. While her job was saved, her team disappeared as part of the cuts. She started looking for jobs, and received lucrative offers from Facebook, Apple, Google and Amazon. When she told Krassner she was leaning toward a lead product manager position at Amazon, he replied with an offer to take over Expectful’s entire business.
“I think it caught her off guard,” Krassner said, who is still a board member at the company. “Usually you don’t think a CEO is looking for [a new CEO] unless things are going to hell in a handbasket.”
The new Expectful
Expectful began as a guided meditation library, which will continue to be its core. But now, Walton wants to take advantage of that momentum and evolve the company into a “go-to wellness resource for hopeful, expecting and new parents.”
The language suggests that the startup is evolving in how it markets itself. Right now, the site has a number of references to “motherhood” and women. But Walton says Expectful defines a mother by anyone who identifies themselves as one. While the startup primarily has content geared toward the gestational parent, or the one who gives birth to the child, Walton says they have a “a partner’s library for non-gestational parents that identify as non-gestational mothers, fathers, or however they choose to identify.”
Walton plans to pivot the startup in three phases: content, marketplace and community.
For content, Expectful wants to organize pregnancy-related information. Currently, a lot of information or advice around pregnancy lives in books or in-person classes. But the learning experience, which Walton says is similar to middle school-style lectures, doesn’t feel built for this century.
The next step in her plan is digitizing the service providers that help women through pregnancy. In simpler words, replace the disorganized recommendations in Facebook groups for parents.
“When I went to ask my OB-GYN for recommendations for a doula, she gave me a sheet of paper with the names of 10 doulas,” she said. “You have to text the doula, ask them questions and if they want to meet up — it all feels yucky.” Expectful wants to put all that information in one platform so moms can access tips and recommendations from the ease of their homes.
The end-product here would be a peer-reviewed platform that can help a mom find everything from a therapist to a live-in nanny, with reviews built-in.
Finally, Walton wants to invest in the community. Expectful recently launched Mother Circles, which connects postpartum mothers into support cohorts led by a doula facilitator. The circles include six weekly video calls, a group chat and 500 hours of on-demand doula support.
Image Credits: Expectful
Part of Walton’s focus through all of these priorities is to invest in Black maternal health outcomes. Her own experience, she says, showed her how even a “Stanford-educated wellness junkie” such as herself can be at a high-risk for pregnancy because of her skin color.
It’s a lofty goal, even with the promising growth and strong library of guided meditations. The competition is steep. One of Expectful’s closest competitors is Peanut, a social network for moms used by over 1.2 million people. Mahmee, a digital support network for postpartum mothers, has raised $3 million and views itself as complementary to Expectful. Headspace has launched its own motherhood meditation series, but it is not as comprehensive as Expectful’s.
“I think we’re able to connect with women in a way that some of these other companies aren’t,” Walton said. “People are paying for the service, so they clearly need it.”
While Walton declined to share new user metrics, she said that the company’s revenue has grown 100% since March 2020.
Long-term, Expectful wants to mimic Peloton’s playbook in terms of getting premium content and community to the right audience. Still, growing from a startup to a venture business requires more than just ambition and market fit. It requires the ability to exponentially grow and keep growing.
A handful of investors believe that Walton’s Expectful can do it. Expectful raised $3 million in a seed financing round led by Harlem Capital. Indicator Ventures, Sequoia Scout Fund, Joyance Partners, Break Trail Ventures, Chinagona Ventures, Powerhouse Capital, AVG Basecamp Fund and Babylist also participated. Angel investors included Ellen Pao, Mike Smith and Ashley Mayer. The round also included $1.2 million in convertible SAFE notes, making the financing round a total of $4.2 million.
“Historically when I look at what black women raise fundraising, I feel fortunate that I’ve been able to raise this round,” Walton said.
Harlem Capital founding partner Henri Pierre-Jacques said that “obviously, given our focus we weren’t going to invest in a white male.” Walton’s “founder-market fit” is what made the firm invest, even with the hairy dynamic of an exiting CEO.
Mayer, head of communications at Glossier, was the one who introduced Walton to the woman who told her about the advisory role of Expectful. She says that Nathalie’s “path to entrepreneurship feels inevitable.
“It was always just a question of finding the space where her passions collided,” Mayer said.
As a new mother and new founder, Walton has had a busy balancing act of a year.
“I’m working more now than I have really in the last decade,” she said. “But I’ve never been more fulfilled because, as someone who went through this, and I’m still going through this, I feel so personally the level of pain that so many women suffer through.”
Source: https://techcrunch.com/2021/02/01/nathalie-walton-expectful-seed/






















































































